Benjamin Eysenbach
Assistant Professor of Computer Science at Princeton University.
Affiliated/Associated Faculty with the Princeton Program in Cognitive Science, the Princeton Language Initiative, and Natural and Artificial Minds.

Room 416
35 Olden St
Princeton NJ 08544
eysenbach@princeton.eduI run the Princeton Reinforcement Learning Lab, where we study the science of intelligent decision making. How can AI systems learn to explore the world and uncover previously-unknown skills or knowledge? Can agents learn about the structure of the world, about the texture of time? How much of this learning can be done in an unsupervised fashion?
We answer these and similar questions by designing AI algorithms. While we might refer to these as ``reinforcement learning’’ methods, many do not use rewards at all; exploration and learning are instead driven by (often much richer) intrinsic feedback. Our group has developed some of the foremost algorithms and analysis for such self-supervised control methods. Here are a few example papers; here and here are some tutorials to learn more about our research.
My work has been recognized by a NeurIPS Best Paper Award, an NSF CAREER Award, a Hertz Fellowship, an NSF GRFP Fellowship, the Alfred Rheinstein Faculty Award, as well as several teaching awards. Before joining Princeton, I did by PhD in machine learning at CMU under Ruslan Salakhutdinov and Sergey Levine. I spent a number of years at Google Brain/Research before and during my PhD. My undergraduate studies were in math at MIT.
My lab’s research is supported by the National Science Foundation, the Sloan Foundation, NVIDIA, Google, Toyota Research Institute, and Princeton University.
Come do science with us! Check out this page for details on how to get involved in the research, whether as an undergrad, PhD student, postdoc, visiting student, or external collaborator.
news
| Jun 7, 2026 |
|
|---|---|
| Mar 15, 2026 | |
| Feb 15, 2026 | |
| Jan 2, 2026 | |
| Dec 1, 2025 |
|
| Oct 2, 2025 | |
| Jul 15, 2025 | |
| Jul 14, 2025 | |
| Jun 11, 2025 | |
| Apr 24, 2025 |
|
selected publications
The aim is to highlight a small subset of the work done in the group, and to give a sense for the sorts of problems that we're working on. Please see Google Scholar for a complete and up-to-date list of publications.
2025








2024






2023
-
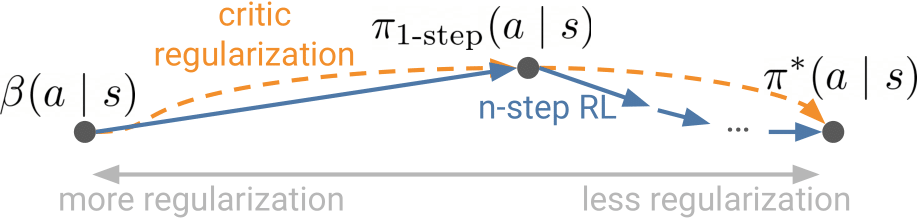 A Connection between One-Step RL and Critic Regularization in Reinforcement LearningIn International Conference on Machine Learning, 2023
A Connection between One-Step RL and Critic Regularization in Reinforcement LearningIn International Conference on Machine Learning, 2023 -
-
 Probabilistic Reinforcement Learning: Using Data to Define Desired Outcomes, and Inferring How to Get TherePhD Thesis, Carnegie Mellon University, 2023
Probabilistic Reinforcement Learning: Using Data to Define Desired Outcomes, and Inferring How to Get TherePhD Thesis, Carnegie Mellon University, 2023














