Contrastive Learning As a Reinforcement Learning Algorithm
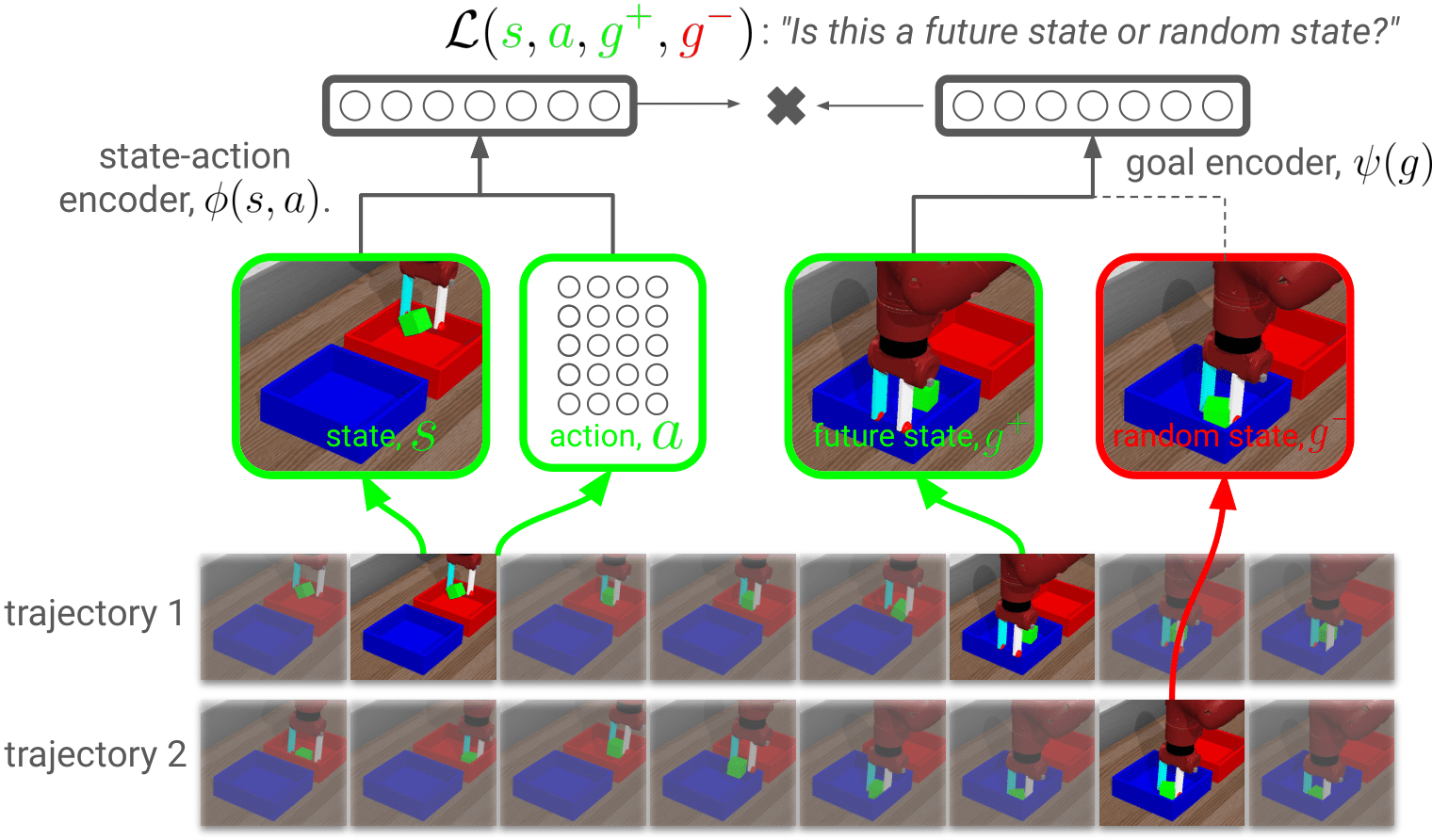
tldr: Representation learning is an integral part of successful reinforcement learning (RL) algorithms, and most prior methods treat representation learning as a perception problem. These representations are typically learned by perception-specific auxiliary losses (e.g., VAE) or data augmentations (e.g., random cropping). In this paper, we take an alternative tack, showing how representation learning can emerge from reinforcement learning. To do this, we build upon prior work and apply contrastive representation learning to action-labeled trajectories, in such a way that the (inner product of) learned representations exactly corresponds to a goal-conditioned value function. Across a range goal-conditioned RL tasks, we demonstrate that our method achieves higher success rates and is more sample efficient than prior methods, with especially large gains on image-based tasks.
Below, we show examples of contrastive RL (NCE) solving some of the image-based tasks in the paper. In each video, the left shows what the agent is observing, and the right shows the desired goal image.